The Blueprint For A Modern Day LLM
A technical guide to the architecture improvements powering today's foundation models — attention, mixture of experts, and beyond.
If you have started to read about how LLMs work but you quickly realized there are many different implementations and new research coming out every day, this should be a helpful guide for you. I'll warn you now that this will read pretty technical, and is not meant to be exhaustive but rather a collection of the most commonly used architecture improvements that I have seen recently.
This blue print focus on training and architecture of the model itself. Stay tuned for another deep dive on inference.
Quick primer for those who are new to LLMs:
Modern day LLMs stack started from a Transformer architecture, most refined & revolutionized by the attention mechanism as provided in “Attention is All You Need”. The basic idea is that you can avoid using compute heavy models like RNNs by creating Query, Key, Value matrices that represent different relationships between tokens (i.e., “words”) Since then, there has been a ton of advancement and research into how to develop capabilities like chat-like responses, reasoning, long-context, etc
You can read more about Attention is All You Need here: https://arxiv.org/abs/1706.03762
Model training evolution
Early models relied primarily on pre-training. What this means is training on a large corpus of unlabeled publicly available data sources and some privately gathered data sources. Common sources you will see sighted include:
- Common Crawl
- Wikipedia
- Books (primarily Gutenberg project)
- Public GitHub repositories
This allows models to understand (1) language and (2) facts. But researchers quickly realized this is not enough to meet the bar for day-to-day interfacing with humans.
Since then, incremental training steps take place to improve the model performance in varying order:
- Supervised Fine Tuning: In this step, the model is incrementally trained on additional labeled data. The purpose of this is to shift the model from responding with free text to a prompt-answer format.
- Instruct training: In this step, the model is trained to understand and follow instructions (e.g., “Create a table” returns an actual table, not “Create a desk” or “Create a song”).
- Chain of thought (CoT) / reasoning training: This typically involves training the model on what is referred to as “chain of thought”. Most models represent this as <think>...</think>, where the model is trained to infer the reasoning process as part of its thinking in addition to the typical prompt response.
- Reinforcement Learning: In this step, the objective is to simulate human preferences and optimize the model to respond in an aligned fashion. The model is trained with multiple responses at a time and is rewarded for being closely aligned to what a human prefers.
- Distillation: In a few cases, companies are building a “foundation” or “base” model that is then used to create a smaller model. The base models are much larger in size (e.g., 200B+ parameters) and then distilled to much smaller ones.
The data used for the incremental training can take many shapes or forms, but typically involves much more processing, human labeling, creating synthetic data from existing models, etc. This has given rise to companies like Scale AI which specialize in these labeled / high quality data sets.
Model architecture evolution
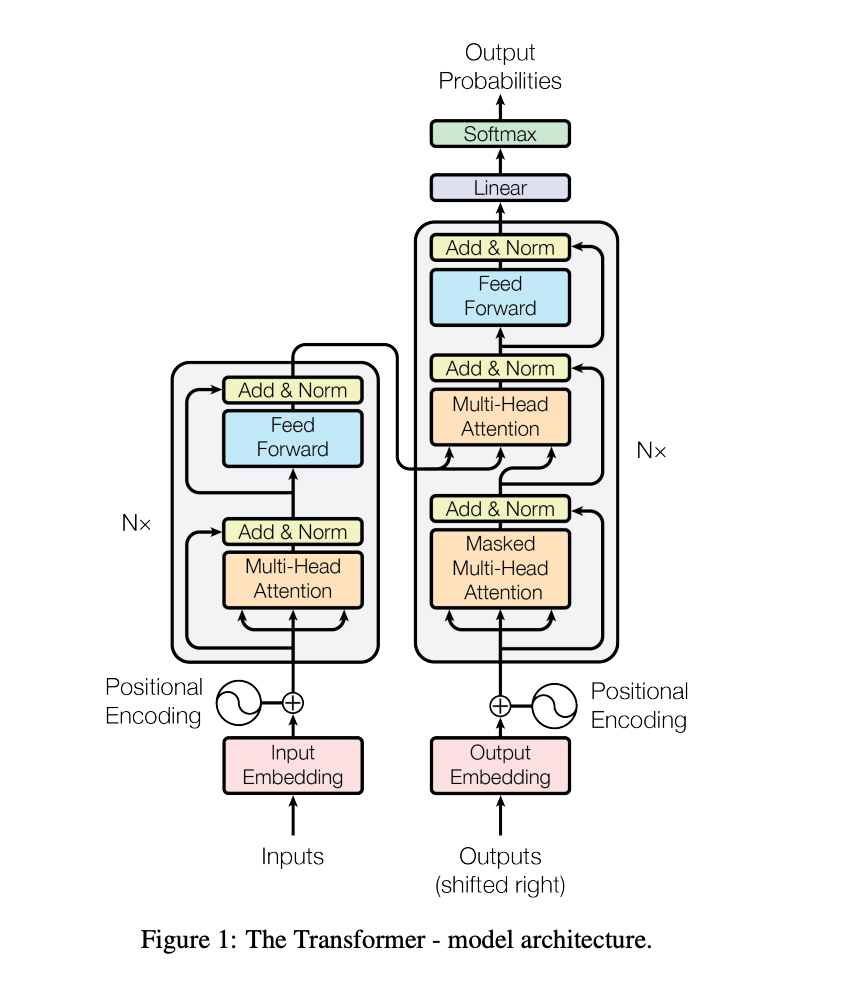
The original transformer model contemplated the following elements:
- An initial embedding layer (which transforms tokens into a numerical vector)
- A positional encoding layer added to the embedding to represent the order in which tokens appear in a prompt
- N Transformer encoder layers which combine:
- Multi-head attention
- Add & Normalization (LayerNorm) layer
- A feed forward layer
- Another Add & Normalization (LayerNorm) layer
You can read more about “All You Need is Attention” here: https://arxiv.org/pdf/1706.03762
Since then, the following evolutions have taken place which have helped the models improve
(A) Multi Modal input
Most modern day LLMs allow multi-modal input (e.g., images, videos, PDFs)
We could write a whole series about the different approaches here, but to highlight a few:
- Early fusion: In early fusion, non LLM models transform the media into features / tokens just as you would text, which are then fed into the LLM embedding layer. Notable uses of this include Llama-4 and OpenAI GPT-4o
- Late fusion: Varies in implementation but the overall concept is to keep separate model structures for different modalities which then integrate at a later step (e.g., in attention)
(B) Mixture-of-Experts (MoE) architecture
If you follow LLMs you have seen how enormous model parameters can get (e.g. 200B+ parameters) parameters. This is computationally and memory very heavy because that means every time you train or run inference on the model, you are activating all these parameters.
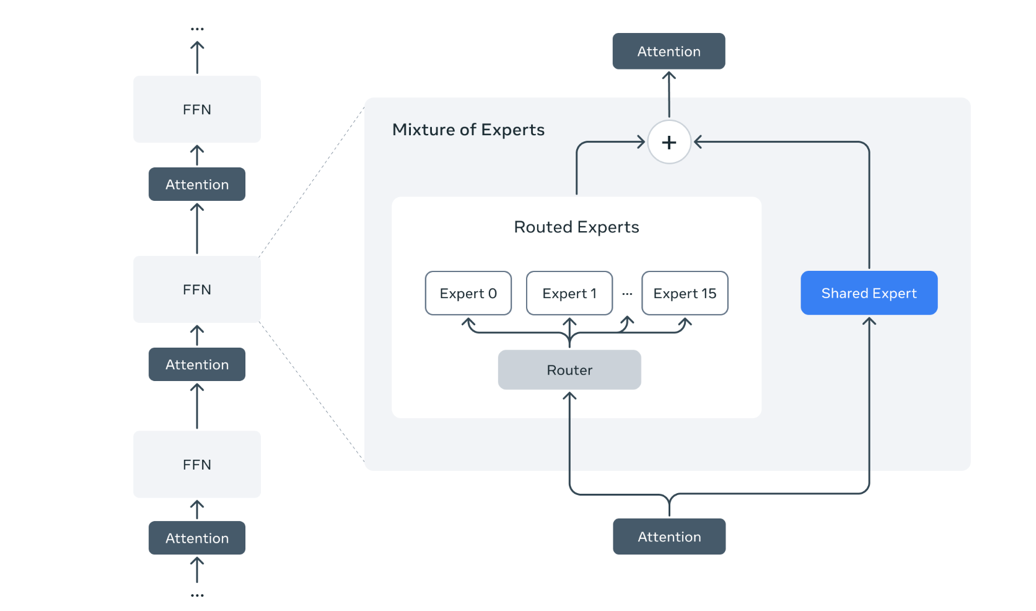
This is where Mixture of Experts come in, replacing the feed forward layer in transformer encoder / decoder layers.
Think of MOE as multiple layers stacked next to each, where each is good at handling specific tokens. This allows selective activation of these layers, as opposed to the previously dense feed forward layers.
Within the well-known models, DeepSeek pioneered this, and other well-known LLMs have quickly followed (e.g., Meta's Llama 4, Qwenn 2/2.5)
Diagram source: https://ai.meta.com/blog/llama-4-multimodal-intelligence/
(C) Attention
As previously mentioned, Attention has been the modern day unlock to what is commonly referred to as AI. However, Attention is a very expensive quadratic computation (N tokens x N tokens), and is the biggest deterrent for context lengths.
Much of the research today goes into (1) how to optimize the calculation in the context of running it on a system, (2) how to distribute the memory load of calculating in a distributed system.
I will share a few of the key ones deployed today:
(1) Flash Attention (1/2/3)
Flash Attention is part of most implementations today and is supported by PyTorch. FlashAttention is an optimization technique that accelerates the calculation by loading different aspects of the Flash Attention calculation into different parts of the GPU memory and by applying tile blocking (i.e., calculating different tiles of the calculation separately and then aggregating / consolidating).
The most recent addition here is Flash Attention 3, which now ships with PyTorch. FA3 takes advantage of new architecture additions in H100 GPUs including how memory is transferred, block-wise matmul and softmax calculations and quantization.
(2) Grouped Query Attention
https://arxiv.org/pdf/2305.13245
GQA is a simplification of the multi head attention model. MHA maintains a separate Q, K, V (query, key, value) matrix per head (which can be anywhere from 8-64). GQA allows LLM developers to maintain a lower number of Q/K across heads while maintaining a similar quality to MHA.
(3) Multi-Head Latent Attention and TransMLA
https://arxiv.org/pdf/2502.07864
Widely adopted by the DeepSeek models, MLA is an approach that compresses the key matrices used in the Attention algorithm into a different projection. This allows for a smaller footprint. TransMLA takes this a step further by integrating more broadly with the Transformer architecture, adjusting different layers (e.g., norm, feed forward) to better fit the MLA approach.
(D) Rotary Position Encoding (RoPE)
https://arxiv.org/pdf/2104.09864
Typical Transformers used positional encoding to reflect where a specific token was positioned in a prompt. This was basically an added number to the original embedding of the token to identify where in the sentence it was positioned.
RoPE improved on this architecture by using rotations and angles as opposed to absolute distances. Notably, it is also a multiplicative function and not an additive function to embedding.
RoPE is one of the mostly widely agreed upon “updates” to the original Transformer architecture.
(E) SwiGLU
SwiGLU is an activation function used as in the linear layer. Historically, ReLU and GLU had been used as the go to activation function. SwiGLU combines two activation functions; (1) The GLU which is a multiplicative activation that includes two learned parameters, (2) the Swedish which is a sigmoid based
(F) FP8 precision training
https://arxiv.org/pdf/2310.18313
Most models historically have been trained on full precision floating points (FP32) or FP16/BF16 mixed precision. Some recent models have opted in to use FP8 (Llama 4, DeepSeek V3). In practice this is highly valuable, because it unlocks a significant amount of memory (e.g., FP32 vs. FP8 training means you can train the same number of weights with ~25% of the memory).
This is one where there are still implementation difficulties, because of the implications of using FP8 on operations that typically require higher precision (e.g., gradient calculation / loss optimization)
Note: this is different from inference using FP8, a practice known as “quantization” which is commonly used by companies / people wanting to run their models with limited memory resources.
(G) RMSNorm (Root Mean Square Layer Normalization)
https://arxiv.org/pdf/1910.07467
Layer normalization has been a standard practice in Transformers. It centers the inputs of a given layer, which has been proven to be helpful in accelerating training and optimizing the loss function.
But, the initial implementation proved to a be an expensive process, having to both center and normalize every input.
RMSNorm opts into a simpler optimization, essentially removing the mean centering and instead just scaling use the RMS of the input.
References
Attention is All You Need (2017)
Chain of Thought (CoT) prompting:
Wei et al., Chain of Thought Prompting Elicits Reasoning in Large Language Models (2022)
Reinforcement Learning with Human Feedback (RLHF):
Ouyang et al., Training language models to follow instructions with human feedback (InstructGPT, 2022)
Distillation:
Hinton et al., Distilling the Knowledge in a Neural Network
FlashAttention
Dao et al., FlashAttention: Fast and Memory-Efficient Exact Attention with IO-Awareness
https://arxiv.org/abs/2205.14135
Tri Dao et al., FlashAttention-2
Grouped Query Attention (GQA)
Ainslie et al., GQA: Training Generalized Multi-Query Transformers
Multi-Head Latent Attention (MHLA)
DeepSeek Research, Multi-Head Latent Attention
RoPE: Rotary Position Embedding
Su et al., RoFormer: Enhanced Transformer with Rotary Position Embedding
FP8 Precision Training
Micikevicius et al., FP8 Formats for Deep Learning (NVIDIA, 2023)
Shazeer et al., Outrageously Large Neural Networks: The Sparsely-Gated Mixture-of-Experts Layer
GShard by Google:
Lepikhin et al., GShard: Scaling Giant Models with Conditional Computation and Automatic Sharding
GPT-4 Technical Report (Mar 2024)
Meta Llama 4 (May 2025)
https://ai.meta.com/llama (Landing page)
https://llama.meta.com/llama4.pdf (Model card/research paper if public)
DeepSeek V2 & V3
https://github.com/deepseek-ai (Code + Papers)
https://arxiv.org/abs/2402.00159 (DeepSeek-V2 base)
Qwen (Qwen-VL, Qwen2, Qwen2.5, Qwen3) by Alibaba
https://arxiv.org/abs/2406.00078 (Qwen2)
https://arxiv.org/abs/2407.03066 (Qwen3)
About Us
NOF1 is a payer policy intelligence platform across clinical and reimbursement policies. Our goal is to transform the way payers, providers, and other stakeholders navigate the complex landscape of healthcare policy to transform the way healthcare is delivered.
Our portfolio of products include:
For payers:
A competitive intelligence platform with over 10K+ clinical policies across payers, UM vendors and CMS. Designed for payers to assess their policy positioning, rapidly research alignment and differences relative to peers.
For providers:
An EMR platform that allows providers to understand clinical policy requirements at point of care, drastically improving documentation quality and compliance while reducing unnecessary denials.
For all stakeholders:
APIs that allow the retrieval of clinical policies in machine readable form and criteria to allow for integration into your enterprise software
To learn more, please reach out to ahmed@nofone.io